Как создать пользовательский трансформер данных с помощью sklearn?

Sklearn — это библиотека машинного обучения для Python, которая в том числе предоставляет широкий функционал по преобразованию данных для разных задач.
В процессе очистки и подготовки данных нам часто приходится делать такие простые операции, как удаление столбцов и пр. Зачем для этого каждый раз писать код с нуля? sklearn предоставляет механизм стандартизации таких преобразований для любых данных и поможет нам создать унифицированный конвейер из нужных действий.
Кроме того, при оценке моделей с использованием кросс-валидации, преобразования данных в исходном датасете не должны приводить к утечке данных. И эту проблему решит создание пользовательского трансформера, а делать мы это будем при помощи класса FunctionTransformer. В нём пропишем сразу все необходимые действия над данными, а потом просто будем его использовать, как и любой другой трансформер в sklearn .
Создание пользовательского трансформера
Всё, что нам нужно сделать для разработки собственного трансформера — реализовать несколько шагов:
- инициализировать класс
transformer; - классы
BaseEstimatorиTransformerMixinиз модулейsklearn.baseдолжны быть дочерними по отношению к нему; - должны быть объявлены методы класса
fit()иtransform(). Чтобы они без проблем встраивались в пайплайн, у них обязательно должны быть параметрыXиy, а функцияtransform()в качестве выходных данных должна возвращать pandas.DataFrame или массив Numpy.
from numpy.random import randint
from sklearn.base import BaseEstimator, TransformerMixin
class BasicTransformer(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
X["cust_num"] = randint(0, 10, X.shape[0])
return X
df_basic = pd.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6], "c": [7, 8, 9]})
pipe = Pipeline(
steps=[
("use_custom_transformer", basicTransformer())
]
)
transformed_df = pipe.fit_transform(df_basic)
df_basic Вот и всё, в пайплайне будут реализованы все операции, прописанные в этом классе. Полученный датафрейм будет выглядеть следующим образом:

Давайте создадим ещё один пользовательский трансформер, применим его к набору данных и даже спрогнозируем некоторые значения. Начнём с импорта нужных библиотек. Они понадобятся нам для выполнения дальнейших операций.
import numpy as np import pandas as pd from sklearn.metrics import mean_squared_error,r2_score from sklearn.pipeline import FeatureUnion, Pipeline, make_pipeline from sklearn.base import BaseEstimator, TransformerMixin from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split
Чтение, подготовка и анализ данных
Будем работать с датасетом из области страхования. В качестве прогнозируемого показателя взята стоимость страховки в зависимости от различных фич.
df = pd.read_csv("/content/insurance.csv")
df_util = pd.get_dummies(data = df,
columns=["sex", "smoker", "region"],
drop_first = True)

Приведённый выше график отображает распределение величины страховых взносов в зависимости от индекса массы тела (ИМТ) клиентов с разделением клиентов по возрасту.
Разобьём данные на обучающие и тестовые в соответствии со стандартным соотношением 70:30.
X = df_util.drop(["charges"], axis = 1)
y = df_util["charges"]
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.30, random_state=42)Теперь создадим непосредственно пользовательский трансформер и используем его для преобразования обучающей выборки.
class CustomTransformer(BaseEstimator, TransformerMixin):
def __init__(self, feature_name, additional_param = "SM"):
print("\n...intializing\n")
self.feature_name = feature_name
self.additional_param = additional_param
def fit(self, X, y = None):
print("\nfiting data...\n")
print(f"\n \U0001f600 {self.additional_param}\n")
return self
def transform(self, X, y = None):
print("\n...transforming data \n")
X_ = X.copy()
X_[self.feature_name] = np.log(X_[self.feature_name])
return X
print("creating second pipeline...")
pipe2 = Pipeline(steps=[
("experimental_trans", CustomTransformer("bmi")),
("linear_model", LinearRegression())
])
print("fiting pipeline 2")
pipe2.fit(X_train, y_train)
preds2 = pipe2.predict(X_test)
print(f"RMSE: {np.sqrt(mean_squared_error(y_test, preds2))}\n") 
Пайплайн используется по причине того, что выполнение всех последовательных преобразований отдельными блоками кода — далеко не самый удобный вариант. Пайплайны сохраняют нужную последовательность операций в едином блоке кода, позволяя одним действием сделать все нужное.
В этом конкретном трансформере пользователь может указывать названия столбцов, над которыми необходимо выполнить преобразования через передачу аргументов.
Далее строим модель линейной регрессии с использованием этого трансформера. Еще он логарифмирует значения, что часто может повысить качество моделей линейной регрессии.
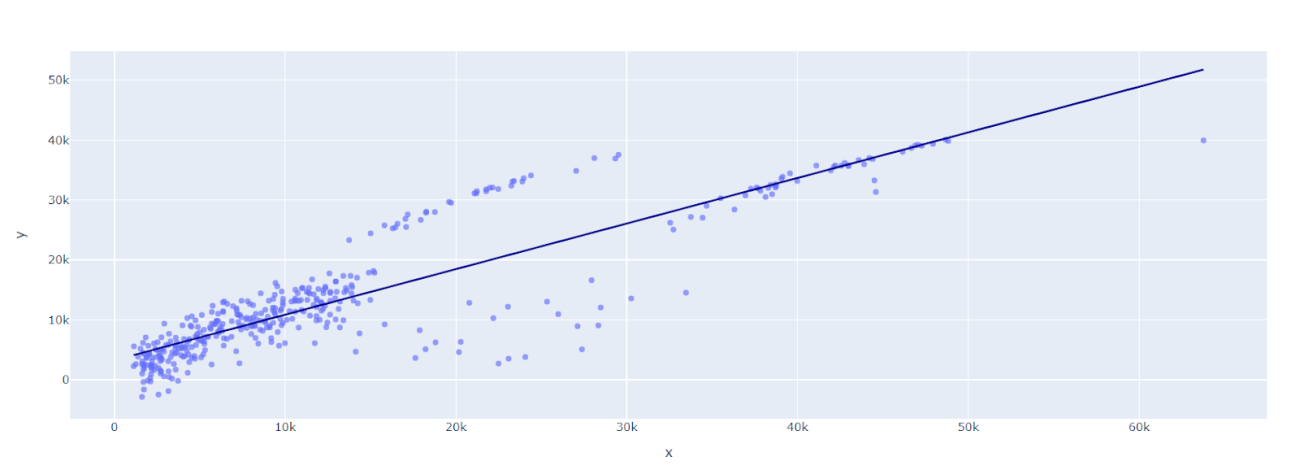
Выше представлен график, на котором отражены фактические и прогнозируемые страховые взносы. Можно заметить, что линия регрессии вполне адекватно объясняет их взаимосвязь.
Вот мы уже можем создавать пользовательские трансформеры и даже использовать их для прогнозирования данных. Но что, если мы захотим настроить трансформеры, предлагаемые sklearn? Давайте модифицируем OrdinalEncoder:
from sklearn.preprocessing import OrdinalEncoder
class CustEncoder(OrdinalEncoder):
def __init__(self, **kwargs):
super().__init__(**kwargs)
def transform(self, X, y=None):
transformed_data = super().transform(X)
encoded_data = pd.DataFrame(transformed_data,
columns=self.feature_names_in_)
return encoded_data
data = df[["sex","smoker","region"]]
enc = CustEncoder(dtype=int)
new_data = enc.fit_transform(data)
new_data[:8]С помощью super() мы можем настраивать любые предопределённые трансформеры в соответствии с нашими потребностями.

Заключение
Пользовательские трансформеры позволяют более гибко и удобно реализовывать подготовку данных, в т.ч. инкапсулировать её в отдельную сущность. Такой подход делает код более понятным. А помимо создания новых трансформеров, можно модифицировать уже существующие из библиотеки sklearn. Попробуйте, пригодиться ^_^.
Источник: Analytics India Magazine