От широких датафреймов в Pandas к длинным и обратно

Изменение размерности датафреймов Pandas — одна из наиболее типовых задач при обработке данных в аналитике. Датафрейм можно переводить и из длинного формата в широкий, и из широкого в длинный. А чем же они отличаются друг от друга?
Давайте рассмотрим простой пример. В таблице ниже показаны средние цены на пять категорий продуктов питания по всем городам США в период с января 2020 года по апрель 2022 года.
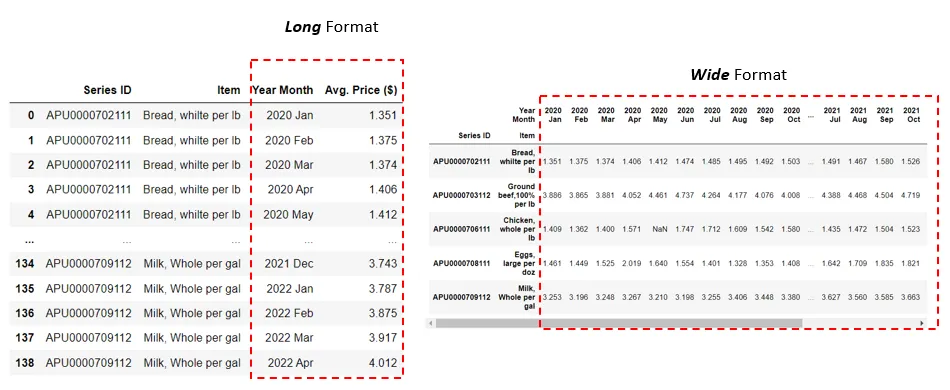
Датафрейм слева имеет длинный формат. Столбцы Series ID и Item представляют категорию продуктов питания. Year Month — это столбец, содержащий все месяцы с января 2020 года по апрель 2022 года. Avg. Price ($) содержит значения средней цены, соответствующие каждому месяцу в столбце Year Month.
Обратите внимание на то, что подобный формат данных подразумевает повторение каждой категории продуктов питания (Item) для каждого соответствующего периода. Хотя у нас есть всего лишь пять категорий продуктов питания, в общей сложности в таблице 139 строк, что делает форму текущего датафрейма «длинной».
Датафрейм в правой же части, напротив, имеет широкий формат. В нём каждая строка представляет собой уникальную категорию продуктов питания. Мы преобразуем столбец Year Month в левом датафрейме таким образом, чтобы каждый месяц находился в отдельном столбце, придавая правому датафрейму «широкую» форму. Так значения столбца Year Month в левой таблице теперь становятся названиями столбцов в правой таблице, а в них указана Avg. Price ($) для каждой категории и периода соответственно.
Теперь, когда мы понимаем разницу между широким и длинным форматом данных, давайте посмотрим, как мы можем легко делать такие преобразования в Pandas. Будем использовать всё тот же набор данных. Данные можно скачать здесь. Давайте сначала прочитаем данные из CSV-файла:
import pandas as pd
import numpy as np
df = pd.read_csv('file.csv')
def f(row):
if row['Series ID'] == 'APU0000709112':
val = 'Milk, Whole per gal'
elif row['Series ID'] == 'APU0000708111':
val = 'Eggs, large per doz'
elif row['Series ID'] == 'APU0000702111':
val = 'Bread, whilte per lb'
elif row['Series ID'] == 'APU0000703112':
val = 'Ground beef,100% per lb'
elif row['Series ID'] == 'APU0000706111':
val = 'Chicken, whole per lb'
else:
val = 'NA'
return val
df['Item']= df.apply(f, axis=1)
df.style.set_properties(subset=['Item'], **{'width': '300px'})
df = df[['Series ID','Item','Label','Value']]
df = df.rename(columns={'Label': 'Year Month', 'Value': 'Avg. Price ($)'})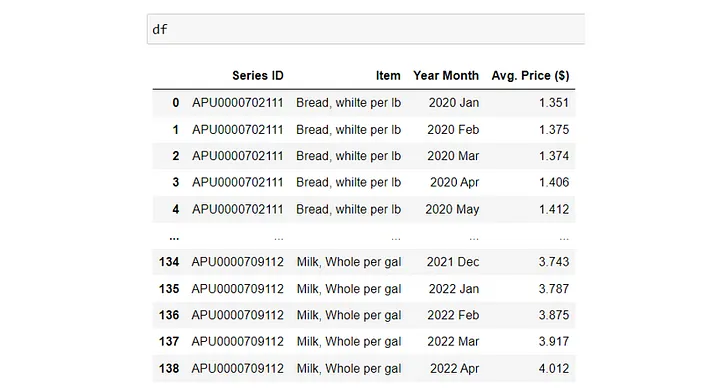
Изменение формы с длинной на широкую
Как мы уже выяснили ранее, по факту этот датафрейм имеет длинную форму. Чтобы изменить его размерность на широкую, мы можем использовать метод Pandas pd.pivot().
pd.pivot(df, index=..., columns=..., values=...)
columns: столбец, используемый для создания столбцов нового фрейма (например,Year Month).values: столбцы, используемые для заполнения значений (ячеек) нового фрейма (например,Avg. Price ($)).index: столбец, используемый для создания индексов (строк) нового фрейма (например,Series IDиItem). Если None, используется существующий индекс.
# Изменение длинной формы на широкую
df_wide = pd.pivot(df,
index=['Series ID', 'Item'],
columns = 'Year Month',
values = 'Avg. Price ($)')
# Перестановка новых столбцов в правильном порядке
cols = df['Year Month'].unique()
df_wide = df_wide[cols]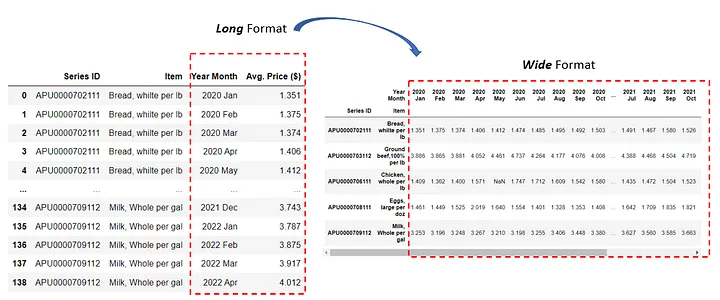
Изменение формы с широкой на длинную
Теперь, как нам вернуть широкоформатные данные обратно в длинный формат? Для этого мы можем использовать метод Pandas pd.melt().
pd.melt(df, id_vars=, value_vars=, var_name=, value_name=, ignore_index=)
id_vars: столбцы, используемые в качестве идентификаторов.value_vars: столбцы, которые нужно вернуть в прежний формат (преобразовать в значения датафрейма). В нашем примере это был бы список столбцов года/месяца ("2020 Jan", "2020 Feb", "2020 Mar" и т.д.)var_name: название, используемое для столбца "variable".value_name: название, используемое для столбца "value".ignore_index: если "True", исходный индекс игнорируется. Если "False", исходный индекс сохраняется.
year_list = list(df_wide.columns)
df_long = pd.melt(df_wide,
value_vars = year_list,
value_name = 'Avg. Price ($)',
ignore_index = False)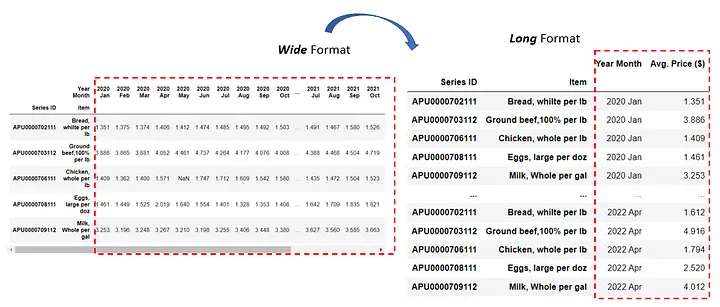
Итого: если вам нужно изменить размер фрейма данных Pandas с длинного на широкий, используйте pd.pivot(). Если вам нужно изменить размер фрейма данных Pandas с широкого на длинный, используйте pd.melt().
Спасибо за чтение! Мы надеемся, что вы найдёте это краткое руководство полезным.
Источник: Towards Data Science